👋 We’re Knock. We provide a set of simple APIs developers use to introduce notifications into their products, without needing to build and maintain a notification system in-house.
Tl;dr: We recently upgraded from Postgres 11.9 to 15.3 with zero downtime by using logical replication, a suite of support scripts, and tools in Elixir & Erlang’s BEAM virtual machine.
This post will go into far too much detail explaining how we did it, and considerations you might need to make along the way if you try to do the same.
It is more of a manual than anything, and includes things we learned along the way that we wish we’d known up front.
Knock relies on Postgres to power our notification workflow engine. From storing workflow configurations and message templates, to ingesting millions of logs and enqueuing background jobs, Postgres sits at the heart of everything our systems do. Our Postgres databases running on AWS RDS Aurora have been consistently reliable, performant, and extensible. This foundation to Knock’s service lets us support with confidence every customer that joins our platform.
Unlike SaaS software that can be constantly upgraded in the background with little notice, upgrading relational databases like Postgres generally requires at least a reboot of the database. In the case of major version upgrades, the database often needs to shut down completely for several minutes in order to upgrade how data is stored and indexed on disk.
The more data you have, the longer the upgrade will take.
In Knock’s case, we have been running Postgres 11.9 since we started the company. Although it has reliably served us at every step along the way, Postgres 11.9 is being retired by Amazon’s RDS service on February 29, 2024. Without taking action (i.e. arranging a long-term support contract with RDS), teams that use Postgres 11.9 on AWS RDS will be forcibly upgraded at that point, likely resulting in forced downtime.
No amount of downtime - scheduled or otherwise - is acceptable for a service like Knock. Our customers rely on us to be online 24/7. Although no service can guarantee perfect uptime, responsible developer teams work to proactively address service issues before they happen.
We added this upgrade to our roadmap in June of this year, with the following constraints:
- Upgrade as many versions ahead as possible, skipping to the latest available version (at the time, Postgres 15.3 for Aurora).
- Any downtime beyond 60 seconds was completely unacceptable, and ideally we would have zero system downtime.
- The upgrade must happen well in advance of Amazon’s February deadline.
- Minimize customer impact (e.g. zero API error responses).
- Operationalize the process so that next time we need to upgrade the database, it is a well-established runbook.
Each of our Postgres databases would need to run through this process, and going from 11.9 to 15.3 would comprise four major version upgrades. If doing an in-place upgrade for each major version would trigger downtime, doing four in a row was out of the question.
In order to meet our requirements, we knew we’d have to get creative.
Preparing for any Postgres upgrade
More than anything, teams seeking to upgrade Postgres in any way should focus on de-risking the upgrade process as much as possible:
-
Make a list of the risks involved in making the migration. For example:
- Unacceptably long downtime
- Data loss
- Changes in database performance for your application’s workload
- Changes in vacuum frequency or behavior
- Are there any replication slots that need to be migrated (this can be tricky - see below)
-
Figure out which risks are the most critical to the project, and which ones might be the easiest to explore/rule out/fix in advance.
Sort the list so the risks with the biggest impact yet easiest to address are at the top.
-
As you develop solutions, consider your list of risks:
- Are there solutions that rule out risks completely?
- Which solutions spread out the risk over time? (So we can more gradually address each step of the migration without taking on too much risk at once.)
-
As you work through the project, always revisit your list of risks, and keep it up to date as you learn new things - including discovering new risks!
✅Incrementally and continually de-risk projects like this until you are confident in being able to deliver on your project goals.
To plan out our upgrade, we started with Postgres’ release notes to get a sense of what was going to change between database versions. This helped us identify more risks (e.g. changes in how Postgres’ vacuum works, requirement to reindex the database when performing certain upgrades) while ruling out others.
As we moved through our planning process, we maintained this list of risks, adding new concerns and updating old ones as we collected more information. While working through the upgrade, we systematically addressed each concern until we were confident we could deliver on our project goals without risking our reliability.
A word about monitoring & metrics
Having thorough instrumentation (thanks DataDog!) to monitor the health of your system and database makes it possible to monitor each step of the migration.
A few key metrics to watch:
- Max TXN ID to avoid transaction wraparound - if this gets too high, your database can shut down and go into emergency maintenance mode
- DB CPU Utilization
- Waiting sessions on your writer instance
- Query latency
- API response latencies for your application
At Knock, we monitor all of these metrics as well as some that are unique to our application, like the time it takes to turn an API request into a notification.
Without timely metrics, you’re flying blind.
Options for upgrading Postgres
Part of our research process included looking for prior examples of database migrations and how the Postgres docs recommend performing an update. Here are a few strategies:
In-place upgrades (a non-starter for zero-downtime upgrades)
The most basic upgrade option for Postgres is an in-place upgrade. On AWS RDS, this upgrade is executed from the AWS console. When performing an in-place upgrade, AWS will shut down the database, run upgrade scripts, and then bring the system back online. Doing this often requires some preparation, including dropping Postgres replication slots, like those used to synchronize with a data warehouse or other systems.
This in-place upgrade process can take anywhere from a few minutes to potentially hours or more - it entirely depends on how much data needs to be updated between Postgres versions.
Often, the system is still not in a fully usable state when it comes online, and
administrators must run maintenance tasks like Postgres’ VACUUM command,
or REINDEX to update indexes to support the new version’s format.
Because an in-place upgrade would require far more downtime than we wanted to tolerate, it was out of the question for us.
A similar approach to an in-place upgrade is to use pg_dump and pg_restore
to transfer the contents of a database once it has shut down.
This dump & restore
approach would also not work for us due to the required downtime involved,
mostly because you need to disconnect all applications from the old database in
order to get a reliable database backup. Even then, for large databases, it can
take prohibitively long to dump and restore the database.
Replication-based upgrades
This approach relies on Postgres’ excellent replication primitives:
the PUBLICATION and the SUBSCRIPTION.
It works something like this:
- Spin up a new database on your target Postgres version
- Copy over settings, extensions, table configurations, users, etc.
- Set up a publication on the old database and a subscription to that publication on the new database
- Add your tables to the publication (there is a lot of nuance here - more below)
- Once it's fully replicated, run tests to satisfy any remaining risks
- Once you are confident in the new database's configuration, point your application at the new database
- Tear down the old database
In the end, this is the option that we chose at Knock for a few reasons:
- It gave us gradual steps we could take towards a migration instead of one big upgrade
- We could test the new database with real workloads and real data to avoid any regressions
- It gave us the most control over when and how to perform the upgrade: once the new database was fully ready, cutting over to the new database took just a few seconds
Although that may sound straightforward, there are several points to consider in this solution that will depend on your application & circumstances.
Configuring your source and destination databases
Publications and subscriptions depend on a few configuration parameters for
setting up replication slots (how the database keeps track of what needs to be
copied from the primary to the follower database).
The Postgres docs
have plenty of detail on these parameters. These parameters will need to be
tuned for your particular application. For simple applications, the only change
necessary is that wal_level should be set to logical.
If you already use replication slots (e.g. to manage a read replica,
database failover, or to keep a data warehouse in sync), then consider setting
max_replication_slots and the other parameters according to the guidance in the docs.
Setting up basic replication
-
Start a new Postgres server on your target version of Postgres (in our case v15.3).
-
Set up your desired databases, schemas, tables, partitions, users & passwords, and everything else.
The target database’s tables must have an identical structure to the source database, but these tables must be empty.
To get a snapshot of the database schema, run
pg_dumpallon the old DB (pass the--schema-onlyand--no-role-passwordsoptions to keep it focused), and then adapt that command for the new DB. You can then compare the generated SQL files to identify and fix discrepancies between the old and the new DB.It may be worth periodically comparing both databases to detect any drift, especially if you have schema migrations happening in the source database. Consider running migrations against both databases to keep them in sync.
-
On the primary instance of the old database, run
CREATE PUBLICATION pg_upgrade_pub;.🚨Although you can tack on
FOR ALL TABLESand that will set up the publication for every table, we found that for large databases, this can lead to performance problems.Instead, we found it worked much better to incrementally add one table at a time to the publication via
ALTER PUBLICATION pg_upgrade_pub ADD TABLE table_name. More on this below. -
On the primary instance of the new database, set up the new subscription pointing to that publication:
-- Note the _sub suffix, you can call this whatever you like CREATE SUBSCRIPTION pg_upgrade_sub -- The connection string can be any standard Postgres connection string. -- More details here: -- https://www.postgresql.org/docs/current/libpq-connect.html#LIBPQ-CONNSTRING CONNECTION 'host=old-db.cloud.com dbname=your_app user=root password=<password>' -- The publication name MUST match the publication created on the old database PUBLICATION pg_upgrade_pub with ( -- This subscription will not start syncing until you enable it, -- which can be helpful when getting started enabled = false, -- Replication slots track the subscription's progress. -- By default, you want Postgres to manage this. -- If you don't create a slot here, you will need to supply one yourself. create_slot = true, -- Generally you want Postgres to copy the contents of each table, -- however for very large tables you may not want this option. -- More details below. copy_data = true, -- This will halt the subscription if something unexpected happens. -- This is usually because of a unique constraint violation, or -- a mismatched schema (e.g. a missing or renamed column). -- We found it helpful to halt the subscription on error so we could -- fix the problem and then resume replication. -- Errors are logged to the database's logs. disable_on_error = true );At this point, you now have a replication pipeline from the old database to the new one.
To enable the subscription:
ALTER SUBSCRIPTION pg_upgrade_sub ENABLE; -- To check the status of the subscription... -- Watch out for subenabled - if it turns false, -- replication is stopped and potentially backing up on the primary! SELECT * FROM pg_subscription; -- More details on monitoring subscriptions using that table here: -- https://www.postgresql.org/docs/16/catalog-pg-subscription.html
Choosing tables to replicate
The next step in the process is to build a list of tables you’d like to replicate. You will want to add tables one at a time, watching each table until all of them are fully replicated. Later in this post we will show you how to monitor replication for all the tables.
Generally, the tables will fall into three based on their disk size and the number of tuples stored in the database.
- Small enough to synchronize in a few minutes: These can be replicated by just adding them to the publication and refreshing the subscription
- Large, append-only tables: These can be synchronize by first replicating only future changes, and then separately backfilling old data from a backup or snapshot
- Large, frequently updated tables: These are the hardest to synchronize, and will require some extra care
For us, "small" was any table using less than 50 GB of storage and 10 million tuples.
Anything over those thresholds we considered "large".
What is a tuple?
Each insert or update to a Postgres table is stored as a "tuple". If a table has
3 inserts followed by 2 updates, the table would have 5 tuples. Tuples are used
by Postgres’ concurrency mechanism (more in the docs).
Postgres’ VACUUM procedure cleans up old tuples that are no longer needed.
When we replicate a table, we replicate all of the tuples that make up the tables contents - inserts and updates. A table with a few rows but many tuples that haven’t been cleaned up will take longer to replicate than a similar table with fewer tuples.
The following query can help determine the size of a database table in terms of disk space and tuple counts:
SELECT
relname AS tablename,
n_live_tup + n_dead_tup + n_mod_since_analyze as total_tuple_count,
pg_size_pretty(pg_total_relation_size(quote_ident(relname))) AS simple_size,
pg_relation_size(quote_ident(relname)) as size_in_bytes
FROM pg_stat_user_tables;
One way to prepare your source database for replication is to VACUUM your tables,
which should help the source database reduce the number of tuples it needs to copy
to the target database. This can help reduce the amount of time it takes to replicate a table.
Before using VACUUM, consult the Postgres docs.
Why does table size matter?
The time it takes to synchronize a table is directly correlated to its size on disk and the number of tuples it contains. The larger the table, the longer it takes to replicate. This is because Postgres needs to copy the entire table over to the new database, and then apply any changes that happen after the initial copy.
The problem with long synchronization time is that it can prevent your primary
Postgres instance from performing VACUUM operations, which can lead to degraded
performance over time. Left unchecked, it can even lead to transaction wraparound
and a forced shutdown of the database.
For these reasons, we added tables one at a time to replication, used different strategies based on the size & write patterns of each table, and closely monitored the system’s performance to ensure we didn’t degrade our service.
If migrating a table becomes problematic, you can remove a table from replication at any time, and then re-add it later (although you will need to truncate the target table and start from scratch).
How to replicate "small" tables
To migrate small tables, you just add it to the publication and then refresh the subscription:
-- On the old database
ALTER PUBLICATION pg_upgrade_pub ADD TABLE my_table_name;
-- ON the new database
ALTER SUBSCRIPTION pg_upgrade_sub REFRESH PUBLICATION;
Postgres will handle copying the table over, getting it synchronized, and applying any further operations to the table. For very small tables, synchronization can happen in less than a second.
Large, append-only tables
Tables that are too large but generally append-only, with no updates (or, if
updates are always on rows that are recent, like within the past week),
then you can set up a separate PUBLICATION and SUBSCRIPTION following the
same steps as above, but setting the copy_data option on the subscription to
false. Suffix the name of the new publication and new subscription with _nocopy
to make it distinct.
When you are ready to migrate these large, append-only tables, you can add them
to this nocopy publication, and refresh the subscription on the target using
the copy_data = false option:
-- On the old database
ALTER PUBLICATION pg_upgrade_pub_nocopy ADD TABLE my_append_only_table_name;
-- On the new database
ALTER SUBSCRIPTION pg_upgrade_sub REFRESH PUBLICATION WITH ( copy_data = false );
We found this approach worked really well for our partitioned tables that stored various types of logs for our customers. We did not need to migrate the root of a partitioned table, we only migrated the underlying tables, and that seemed to work pretty well.
Once the subscription is running, you should start seeing logs appear on the target databases table:
SELECT COUNT(*) FROM my_append_only_table_name; -- Returns more than zero
From here, you can backfill any records older than those now visible in the
database using whatever means you like (e.g. pg_dump).
Here is how we did it on AWS RDS Aurora:
-
Take a snapshot of your production database in the AWS Console
-
Restore that snapshot into a new database instance (the snapshot DB)
-
Rename the table(s) on the snapshot DB that you want to replicate by adding a suffix like
_snapshot. This prevents us having two replication pipelines feeding into the same table on the target database. -
Create the same table(s) on the target database with the same schema as the snapshot database. Use the same suffix as above.
-
Create a publication on the snapshot database and a subscription on the target database to replicate these snapshot table(s) from the snapshot database to the target database
-
Enable the subscription and monitor its progress
-
Once the subscription is caught up, you can merge the tables together using
INSERT...ON CONFLICT:INSERT INTO my_append_only_table_name SELECT * FROM my_append_only_table_name_snapshot ON CONFLICT (id) DO NOTHING;
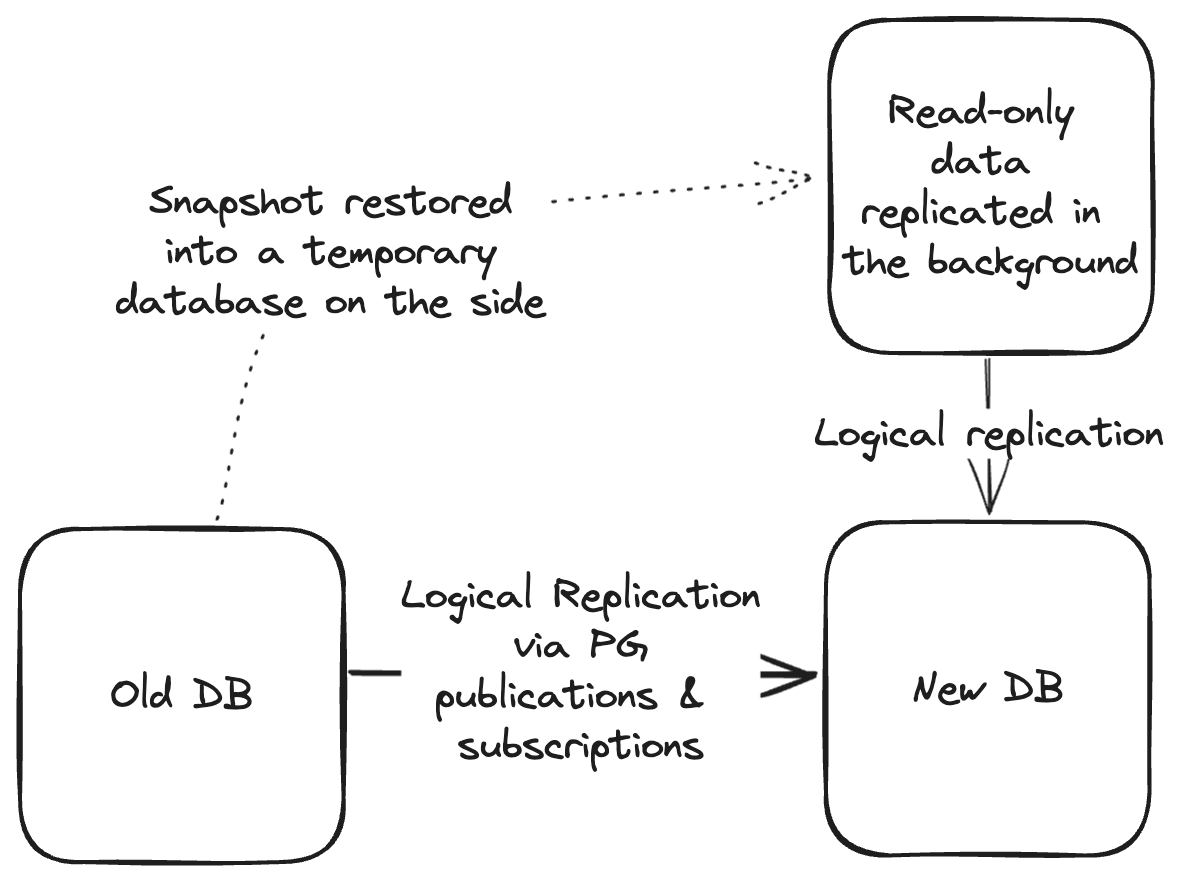
For very large tables, this can still take several days, but because it’s all in the background it shouldn’t affect your production environment.
Once the tables are fully merged, compare them to ensure a consistent row count (more on that later). Once you are confident the tables are identical, drop the snapshot table on the target DB, drop the subscription to the snapshot DB, and terminate the snapshot database instance.
Large tables with many updates over most of the rows
These are the hard tables. Because they have so much data in them, they can
take a long time to replicate, which can affect system performance on the
source database if it prevents AUTOVUACUUM from running. Because they have
so many updates, we can’t treat it as an append-only table.
A few points to consider:
- Is there any housekeeping you can do to reduce the table’s size?
- Have you vacuumed the table recently?
- Can you partition the table into smaller pieces?
- Do rows stop receiving updates after a reliable time frame (e.g. 1 week?) - this could be used to treat the table as an append-only table, and then after that time frame has elapsed you can backfill old rows from a snapshot.
If your source database is not on PG 15 or greater, your options are limited. Follow the steps in the "small tables" section. Rely on the monitoring you have in place (you do have monitoring, right?) to ensure replication doesn’t degrade your service. If needed, you can rollback by removing the table from the publication, and refreshing the subscription (See below).
If the table is still too big, try to start replication during low traffic times to reduce load and write activity. This will hopefully minimize the impact on your system.
Large tables coming from PG 15 or greater
If your source database is on PG 15 or greater, you may be able to split up replication across multiple publications (similar to partitioning or sharding). You can then migrate the table in smaller chunks, at the expense of using more replication slots. The Postgres docs have more information on setting these parameters.
Because we migrated from 11.9 to 15.3, we did not have this option available to us. As such, we have not tested this approach. Even so, as we considered our options we noticed that this approach might be possible. If you try it out, let us know, we’d love to hear how it goes!
The goal is to have enough publications to split your largest table into manageable
pieces (for us, this was about 100 GB of non-index data stored). We’ll assume we
are splitting across three partitions in this example. The trick is adding a WHERE
clause that splits up the rows handled by each subscription:
-- On the source database
-- For three partitions...
CREATE PUBLICATION pg_upgrade_pub_0;
CREATE PUBLICATION pg_upgrade_pub_1;
CREATE PUBLICATION pg_upgrade_pub_2;
ALTER PUBLICATION pg_upgrade_pub_0 ADD TABLE big_table
-- id must be the primary key.
-- Use hashint4 for int IDs, hashint8 for bigint IDs
-- Use hashtext(id::text) for UUID or other key types
-- If you have a composite PK, concatenate the columns together before hashing as text
-- Postgres' hash functions return positive & negative numbers - we abs() the result to make it positive
-- % 3 is used to pick which of three partitions. Adjust the integer for the number of partitions you will create.
-- = 0 assigns rows to the first partition (zero-indexed, so we will finish with partitions 0, 1, and 2)
WHERE abs(hashint4(id)) % 3 = 0;
-- Repeat the above ALTER statement for each publication, adjust the where clause accordingly.
On the destination database, create a subscription for each partition.
You only want to migrate one slice of each table at a time. Generally, you will
follow the same instructions as adding a "small" table, but with the extra WHERE
clause added when setting up the table for each publication.
In this way, you can slice up large tables into smaller, more workable pieces.
Consider only using this approach if having too many replication slots is a
problem: you can still add "small" tables using this approach,
just add the table to the _0 publication without a WHERE clause.
This can help reduce the number of replication slots required when migrating.
Checking a table’s replication status
When a table is added to a subscription, it moves through five distinct states
(visible on the target database under the system table pg_subscription_rel
in the srsubstate column):
- Initializing the table’s subscription (State code
i) - Copying the table’s contents in one efficient operation (State code
d)
This step requires keeping old Postgres transaction IDs around, which prevents vacuum from running effectively and can lead to system performance issues and (if left running long enough) even Postgres transaction ID wraparound which can halt the system.
This is the step that requires replicating only one table at a time.
- Copy finished, waiting for final sync (State code
f) - Finalizing initial sync (State code
s) - Ready and running under normal replication (State code
r)
In order to prevent the issues found in step 2 above, we found it was necessary to add one table at a time to replication, and to closely watch the system’s performance. The worst-case scenario (transaction wraparound) must be avoided.
If you get anywhere close to wraparound, it is better to abort the migration and break it up into smaller pieces.
If we had created our publication using the FOR ALL TABLES option, Postgres
would have started to sync our very large source database all at once,
preventing automatic VACUUM operations from completing necessary maintenance.
We found this to gradually degrade database performance over time,
leading to increased risk to system stability.
Adding one table at a time has the added advantage of allowing teams to incrementally migrate each table. Replication does come with CPU and other costs for the source and destination databases. By adding one table at a time, administrators can control how replication affects the running system.
Aborting the replication of one table
If you need to halt the replication of a table, you reverse the instructions for adding the table in the first place:
-- On the old database
ALTER PUBLICATION pg_upgrade_pub_nocopy DROP TABLE my_append_only_table_name;
-- ON the new database
ALTER SUBSCRIPTION pg_upgrade_sub REFRESH PUBLICATION;
In an emergency, you can also drop the publications and subscriptions entirely, and start the process over. Postgres will clean up any replication slots that were created as part of the publication and subscription, which should relieve any pressure on the source database.
Be advised that if you just disable the subscription without removing the table from the publication and refreshing the subscription, the source database will continue to hold onto old transaction IDs, which can lead to transaction wraparound and a forced shutdown of the database.
Just disabling the subscription will not resolve any replication-related performance problems.
A note about moving replication slots
Replication slots in Postgres store a log of database activity that can be consumed on another database or in another application. Postgres tracks slot progress using a Log Sequence Number (LSN). LSNs are unique to the primary Postgres database. This means that if you have a replication slot on your database (e.g. to copy changes to a data warehouse or as part of your own application), you will not be able to copy the replication slot's LSN over from the old database to the new database.
You will need to consult the documentation of the application consuming the replication slot to decide how to best migrate (e.g. for data warehousing tools, they may have a way to merge duplicated information between both databases). If you’re using replication slots as part of your own application, you already know that you’re on your own to roll your own solution. Having some idempotence mechanism to deduplicate transactions from the old and the new database will definitely be helpful.
Finalizing the migration
Once you have added all of your tables to publications, and the subscriptions have caught up on everything, you need to now verify that the tables match.
Unfortunately, eventual consistency (the lag between a write being applied to the old database and it showing up on the new database) will prevent both databases from being perfect matches at the same time, you can still count table rows to make sure you’re close enough to know it’s working.
At Knock, we wrote a script that iterated through each table and asked both
databases to count the total number of rows in each table on the old and new
database, and compared the results. For tables with an inserted_at column, we
filtered to rows older than 10 seconds. This interval is more than enough to
prove that the tables match, with the assumption that the remaining 10 seconds
will replicate across in short order.
You may need to come up with a strategy that fits your application’s needs. We felt that as long as row counts were accurate within a few seconds, we could otherwise assume that Postgres replication was reliable.
In a few instances, we also spot-checked the contents of a few tables to ensure they matched to confirm this assumption. Collecting a random sample of rows from tables and comparing them between the old and the new database can help verify that the tables are identical.
Application-level changes
Parallel to all of this database work, you may need to change your application to connect to both databases. When you are finally ready to cut over, you need a strategy to shift traffic to your new database.
When the final cutover happens, you could change your application’s configuration to point to the new database, and then reboot your app. This is simple, straightforward, and is precisely how we migrated one of our lower-traffic databases.
For applications with lots of concurrent activity, you may need to get creative. We wanted to avoid a situation with conflicting writes between the old and new database. Such conflicts could have caused a service outage for us, requiring manually reconciling database state.
At Knock, we configured our application to connect to both databases. When we were ready to execute the cutover, we ran a script that did the following:
-
Tell all instances of our application to send new queries to the new database
-
All currently running database queries had 500 ms to complete before being forcefully cancelled
-
For the first second after flipping the flag, our application artificially paused any new database requests for one second. This allowed pending transactions to replicate to the new database so that new queries wouldn’t have stale reads
500 ms is far higher than most of our db queries, and we saw zero errors due to forced disconnections
-
After that first second, database activity returned to normal behavior, but pointing at the new database.
-
In the middle of the cutover, we had some specialized database workloads that the script shut down and restarted in order to reconnect to the new database.
One more thing: sequences
One thing that replication doesn’t synchronize is any Postgres sequence. Sequences are monotonically increasing integers that are guaranteed to never duplicate. Unfortunately, they are not incremented on the new database as sequence values are used up on the old database.
Fortunately, this is pretty easy to control for. Part of our cutover procedure was to run a script right before flipping our feature flag that did the following:
-
Connect to both databases
-
Get the next value of all of the sequences in the database using
SELECT nextval('sequence_name') -
Set that value in the new database using
SELECT setval('sequence_name', value::int4 + 100000)to advance the sequence and offer a little bit of buffer (in this case, 100k rows can be added between setting this value on the new database and cutting over). This will introduce a gap in the sequence, but that’s generally not a problem. For us, our sequences are bigints. 100k values skipped in the sequence is a rounding error off of 0% used up sequence values in that case.You will want to tune how big of a gap you introduce so you don’t use too much of your sequence’s usable space. If you only expect the sequence to use a few hundred values during your cutover window, then maybe advance it only by 5000.
Final checklist before cutting over
Here are some of the things we considered before executing our final cutover:
- Do the rows on all the tables match as expected?
- Are all the subscriptions enabled and running without error?
- Do the schemas match? Can you freeze any new schema migrations from being released to reduce the risk of something changing while you’re migrating?
- Is your new database properly sized for your workloads?
- Do you have to add any read replicas so the database cluster topology is the same between the old and the new database?
- Have you reindexed and performed basic VACUUM maintenance on the new database to ensure it’s fresh and ready for production traffic?
- Have you double checked Postgres’ release notes for anything that might cause a regression in your app?
- Have you run automated and manual tests against a staging database on the new version to verify system performance?
- Have you run load tests of your most demanding queries using
pg_benchagainst your new version to verify performance? - If there’s one thing that you can de-risk still, what is it?
- Do practice runs in a staging or test environment until you have fully exercised the cutover process multiple times. Dry runs like this will help reveal gaps in your plan before you go to production.
- Right before cutover, take a database backup - just in case.
Cutting over
At Knock, we took a few weeks replicating tables one at a time. We generally did this after business hours and during our lowest traffic time frames. We practiced cutover in our staging environment multiple times, ironing out the process until it just worked without much operator involvement.
Once we had a replica running PG 15 and had the application code in place to cut over from the old to the new database, we ran one final set of checks and flipped the flag.
After months of preparation, the actual cutover was uneventful: our application cut over within a few seconds, we had a brief blip of (intentional) latency as queries waited to allow for replication, and our application continued running without skipping a beat. Reading this paragraph took longer than the cutover itself.
From there, we rolled back the application changes we introduced, permanently pointed everything at the new database, removed the subscriptions on the new database, and tore down the old database. We had successfully jumped from Postgres 11.9 to 15.3 with zero downtime!
Conclusion
Although jumping four major versions of Postgres in one leap is a painstaking process, it can be done, and in many ways it’s safer than scheduled downtime: it can be practiced, tested, and reworked multiple times before performing the actual cutover. At any point in the process, we could have dropped the publications from the old database and started over without degrading our service.
Modern customers expect 100% availability. While that is not technically possible, zero downtime migrations make it easier to keep systems running smoothly without major service interruptions.