We’re Knock. We run flexible notifications infrastructure that developers use to schedule, batch, and deliver hundreds of thousands of notifications every month.
We believe that SaaS products like ours should give you better visibility and observability into what’s going on than if you built it yourself. Our built-in debugger is part of that belief, enabling customers to jump from API request to logic engine execution to message sent. We have millions of API logs in our database for our customers to comb through. That mountain of logs grows every day. Logs are generated for every API request and are buffered in an AWS Kinesis Data Stream before we write them into Postgres.
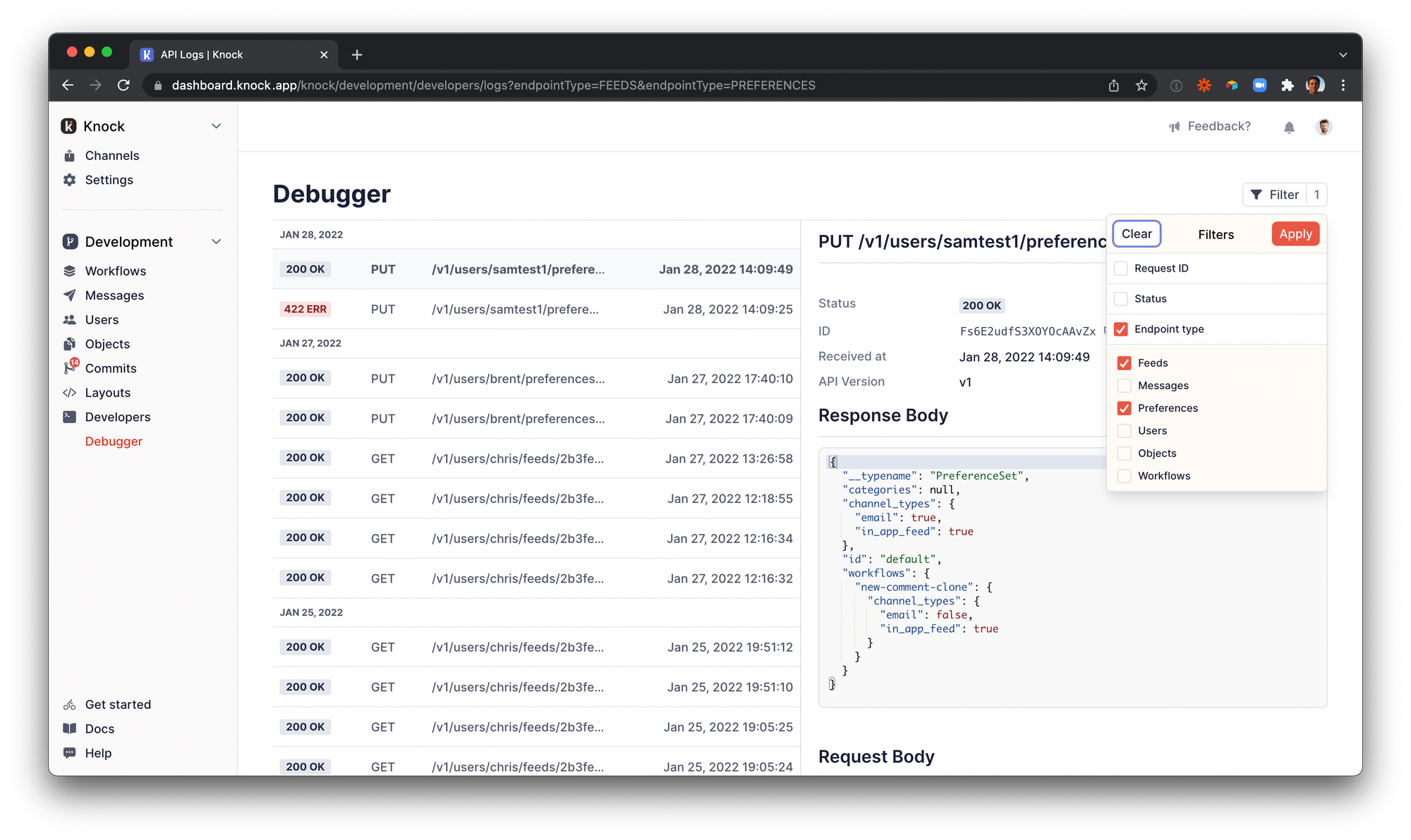
We knew that our customers would need to be able to filter by endpoint in order to find the API logs that are most useful to them. Given the volume of logs and that some features span across multiple different API endpoints, we needed something that met a few important criteria:
- Search across millions of rows spanning over multiple months
- Let us perform partial matches on API paths (e.g. pick out all preferences with a query like
*/preferences) - Add logs with just one INSERT operation per batch of logs into Postgres. This means no normalized tables, and no querying for data before doing an insert.
At this point, dear reader, you might ask, “Why not just use a Lucene index database like ElasticSearch, Apache Solr, or my preferred solution to this problem?”
Because we are such a small, early team, we knew keeping it simple now would help us move faster. As our needs evolve, we probably will migrate to a purpose-built log storage database. We designed our log search experience to be easy to migrate to a new backend so we can retain future options without sacrificing short-term productivity.
That's why we took the time to ensure Postgres can perform until we make such a migration.
🧵 Searching Across API Paths
We use RESTful API design at knock. So, our API paths like GET /users/:id/preferences are inherently tree-structured, going from least specific to most specific in detail. We knew that if we wanted to be able to quickly surface the features tied to a given log entry, this API path would be our starting point.
We first considered mapping each request’s path to a list of features by name, so e.g. /users/:id/preferences would become something like ["users", "preferences"].
We could store that JSON array in Postgres as a JSONB value, but it seemed that could be a potential speed bump as Postgres dug into each array and its corresponding values. Even when indexed, it didn’t seem like the best datatype for the job, so we scrapped that idea.
We considered using strings and LIKE expressions (SELECT ... WHERE feature_type like '%/preferences') or regular expressions to find what our users are looking for. This also seemed to be a performance pitfall, however, as it would require a lot of database CPU work and may not be index optimized.
At this point, we remembered a data type built into most Postgres distributions (including Amazon Aurora for Postgres, which we use): The Label Tree.
🌳 LTrees, or why we love Postgres at Knock
Postgres ships out of the box with the LTree data type (short for “Label Tree”). LTrees represent hierarchies using string labels joined together with periods, like StarTrek.Series.TNG or Science.Physics.Astrophysics.
LTrees are perfect for storing and searching over hierarchies of strings. One very familiar type of label tree is the domain name system (DNS) that powers the internet. When you visit www.knock.app or web.archive.org, you are writing a label tree that starts at the edge (e.g. www), moves down the tree (knock) and ends at the top-level domain or TLD (e.g. app). Note that DNS puts the “root” of the tree at the end with the TLD whereas other trees (like API paths) might start at the front.
Using LTrees, one could build a database for every DNS entry on the internet, and then answer questions like “How many .com domains are there?” or “How many Apple.* domains are registered?” or “How many websites use www as their first-level subdomain?” without resorting to inefficient Regex or string wildcard searches.
Other examples of trees like this include version numbers like 2.10.5 or 1.7, files on your file system, departments in an organization, and the Dewey Decimal System on books at the library.
If we could convert our API paths into an LTree, we could use index-optimized queries to get exactly what we were looking for.
✍️ Writing Label Trees
The first step to use LTree in any Postgres database is to enable the feature (as an Elixir shop, that was in a Phoenix migration):
CREATE EXTENSION IF NOT EXISTS ltree;From here, we needed to normalize each API path into an LTree. We came up with the following formula:
-
Start with the API path
/v1/workflows/my-awesome-workflow/trigger -
Trim the API
/v1/prefix off the frontworkflows/my-awesome-workflow/trigger -
Remove any parameter tokens
workflows/trigger -
Replace each
/with a.to form an LTreeworkflows.trigger
As part of our Phoenix app’s compile step, we actually build a map of each API path/feature type pair, which makes normalizing each API path extremely fast at runtime.
When a batch of API logs arrives in our Broadway message processing pipeline, we can quickly normalize each record’s API path and write the entire batch at once in a single INSERT operation. This makes it possible to ingest large volumes of logs quickly, while also taking advantage of a read-optimized and fully indexed data structure.
Although LTree supports Postgres’ default B-Tree index type, using a GiST index enables LTree’s custom operators like searching by label adjacency or wildcards.
🔎 Seeing the forest for the LTrees
With our logs reliably written and indexed in batches, we could now turn to searching across our logs using the feature type.
When a customer goes to search their API logs by feature, we can use simple LTree queries to quickly find what they are looking for. These queries use the ~ operator, and use a regex-like syntax. More details on the syntax are in the official Postgres docs on LTree.
For example, to find every API log under a /users endpoint, we use a wildcard * :
SELECT * FROM api_logs WHERE feature_type ~ 'users.*'This will pull up any two-element LTree starting with users. If we want to get values starting with users but with any number of labels, we can say *{0,} (meaning “match zero or more labels”).
Preferences need to search across users.preferences and objects.preferences. Some of our preferences endpoints may also have more than two labels. Even so, the query is short and sweet:
SELECT * FROM api_logs WHERE feature_type ~ '*.preferences.*{0,}';The query plan for that query shows that it relies on a Bitmap Index Scan for each of our partitioned tables. This means that we can avoid costly sequential table or index scans, and that we only load each data page once while getting the list of rows to return.
🛫 Takeaways
The data types at the heart of any system define how good the rest of the system is. So, become familiar with the data types available in your tools. Although Postgres has far more features than we can document, here are a few gems (explore the Postgres docs to find the best fit for your projects):
hstoreto efficiently store maps of data- Bloom filters with
bloom ginandgistindexes for full-text search- Case-insensitive text fields with
citext - Cubic data shapes with
cube - PostGIS for geographic data...
- ...or
earthdistanceif you just need to find the length of an arc on a perfect sphere isnfor handling barcodes in standard formatssegto model line segments- Many other geometric types like
point,box,lseg,line,path,polygon, andcircle tcnfor reacting to inserts, updates, and deletes