We’re Knock. We run flexible notifications infrastructure that developers use to schedule, batch, and deliver notifications to in-app and out-of-app channels, without the need to write custom application code.
Here at Knock, we use a set of PostgreSQL database instances as our primary datastore. We use this database to store Knock workflow configurations, along with records for all the notifications we deliver.
As Knock has grown, we’ve found ourselves tuning the indexing strategy on some of the tables in this database. In this post, we walk through some of the key lessons we continue to reference as we evaluate how to index our tables.
1) Each index has storage and write cost
Postgres indexes are “secondary indexes”. For each index you create, Postgres creates a separate model (essentially another table) for storing the indexed data. This setup comes with some costs.
Each additional index takes up more space on the disk. In turn, every table write requires companion writes to the indexes. It will become more expensive to issue writes to a table as the number of indexes increases. This will become especially apparent as the size of the table itself grows too.
Be careful not to over-index your tables.
2) Postgres can choose many ways to query (or not query) indexed data
Indexes also have a read cost. Each index hit will require at least two I/O operations to resolve: one that fetches data from the index, and a second that fetches the data from the table.
The query planner may determine a direct read from the heap is preferable to the cost of an index scan, even if there are index hits available. It’s most common for Postgres to choose this path if the index scan itself would return a significant portion of data in the table. As a result, Postgres frequently skips over indexes for small tables.
NOTE: In Postgres internals, tables are called
heaps. When examining query plans, if you see phrases such as “heap scan”, this is synonymous with reading data from a table.
Another thing to consider is the Postgres page layout model. Postgres stores table and index data as a set of fixed-size “pages”. Each page contains metadata about the data structure, plus some rows of data.
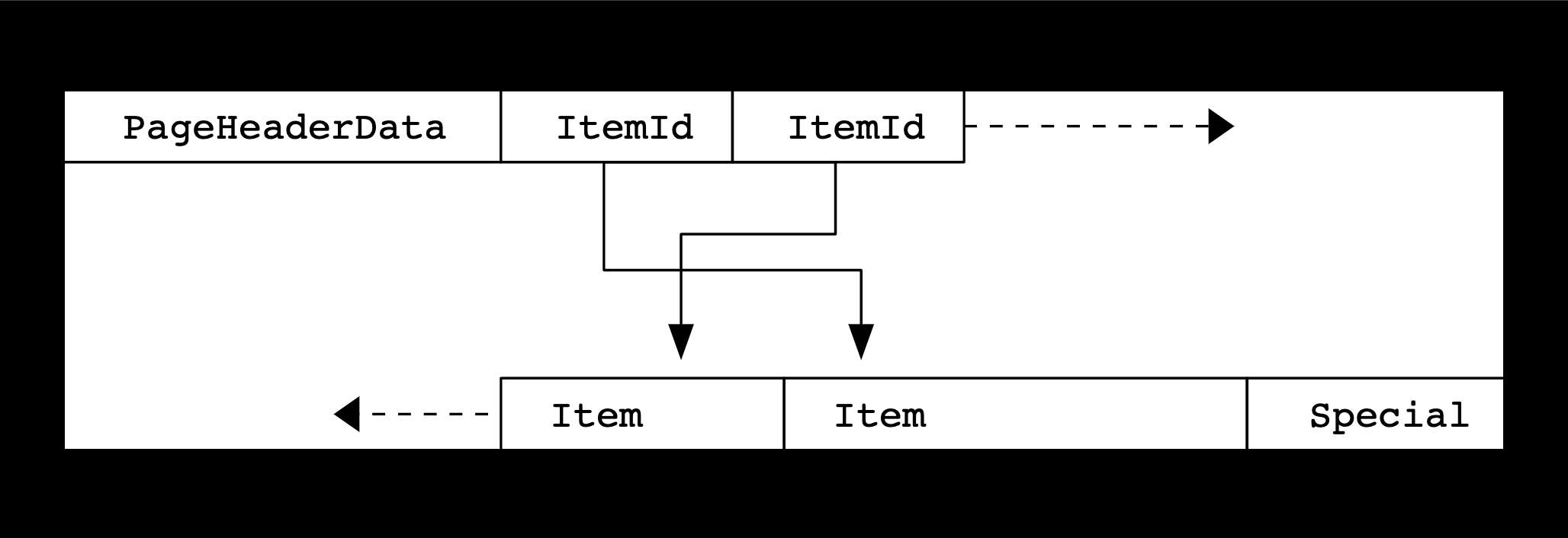
The PostgreSQL page layout model, visualized. Source: PostgreSQL docs.
A basic index scan will pull full rows from the index as a page, but can only hold a single page of rows at a time. When data pulled from an index exceeds the page-size limit, Postgres will instead opt to construct an index “bitmap”. The bitmap is a simple data structure that pairs the identifier for a row with its location in the heap. Postgres will then use the bitmap to retrieve the actual rows from the table as part of a heap scan.
Bitmaps allow Postgres to pull large result sets from an index, even those that exceed the page-size limit. But, because more data needs to pull from the table itself, bitmapped index scans are generally more expensive.
Postgres will consider these factors (plus many more) to determine how it will execute each query. If you examine an EXPLAIN ANALYZE result, you’ll see within the query plan one of the four ways Postgres chooses to read data from the available indexes:
- Sequential Scan — Postgres will read data from the heap directly, avoiding any indexes.
- Index-Only Scan — Postgres will scan only the index itself to return rows from a query. This is the one and only case where Postgres doesn’t touch the heap and the scan doesn’t require multiple I/O operations! But, index-only scans are not common. They only apply when A) every filter in your query is present in the index definition; and B) Postgres can determine row visibility from the index result, which is only possible for sparsely written tables. In short, index-only scans are only available to simple queries on tables with little write activity. See the Postgres docs on index-only scans for much more detail on the topic.
- Index Scan — This is the basic index scan, where Postgres reads data from the index into a page and then from heap. Additional filters not part of the index will be applied during the heap scan step.
- Bitmap Index Scan — This is the bitmap-based index scan, where Postgres reads data from the index into a bitmap, and then uses the bitmap to look up the actual data from the heap.
As a general rule, Postgres will choose the most efficient query plan with the indexes made available. It’s not uncommon to see different plans for slightly different queries on the same table.
3) Know when to use combined indexes versus multicolumn indexes
Bitmap index scans enable another key feature in Postgres: using multiple indexes to resolve a query. The query planner may choose to execute multiple bitmap index scans for a query, and then combine them via a BitmapAnd / BitmapOr step into a single structure for scanning the heap. This is possible since Postgres can perform the bitmap combination with a high degree of efficiency.
So, you might ask yourself, why does Postgres also offer multicolumn indexes?
CREATE INDEX my_multicolumn_index ON my_table (column_a, column_b);Once again, the answer comes down to I/O cost. Combining bitmaps may be efficient, but each additional bitmap scan adds cost to the total query. In addition, multicolumn indexes are more selective and generally return fewer results. This means a more efficient heap scan step.
Regular index scans targeting all columns in a multicolumn index will often outperform combined bitmap scans. They are especially useful when multiple queries are issuing the same multi-column constraint.
In contrast, combined bitmap scans allow you to leverage the Postgres query planner when issuing highly variable queries.
4) Consider the leading-column rule for a multicolumn index
While multicolumn indexes can outperform combined bitmap index scans, they definitely will not outperform in all query plans.
Multicolumn indexes are sensitive to the ordering of the columns as defined by the index. Specifically, multicolumn indexes are most efficient when a query contains filters that hit the leading columns in the index. As the Postgres docs put it:
A multicolumn B-tree index can be used with query conditions that involve any subset of the index's columns, but the index is most efficient when there are constraints on the leading (leftmost) columns.
CREATE INDEX my_index ON my_table (column_a, column_b, column_c);Using our example index above, we can work through the application of the leading-column rule:
- A query that filters by
a AND b AND c, will be the most efficient againstmy_index. - A query that filters by
a AND bwill be very efficient, and will likely perform better than two bitmap index scans against the same columns. - A query that filters by just
acan usemy_indexefficiently, but it will be less performant than an equivalent index onaalone. - A query with any gaps in the leading columns (e.g.
a AND c,b AND c, or justc) will not be efficient.
5) Use sorted indexes to boost performance for ordered queries with a limit
All B-tree indexes in Postgres are stored with an order. The default order is ascending with null values last, but it’s possible to define an explicit sorting override to your index definition. You can choose the order of the sort, along with the placement of null values in the ordering (beginning or end).
CREATE INDEX my_sorted_desc_index ON my_table (inserted_at DESC);
CREATE INDEX my_sorted_asc_index ON my_table (inserted_at ASC NULLS FIRST);Once in place, Postgres can choose to use the sorted index to order query results, eliminating entirely the need for a step to sort the results from the heap.
Sorted indexes are ideal for queries that combine an ORDER BY clause with a LIMIT clause. In these cases, Postgres can do a simple scan of the index to retrieve the first N rows. A normal sorting operation, in contrast, would need to sort all possible records to know the first N to return.
However, when sorting without a limit constraint (or a very large limit), a regular sort step will almost always be more efficient, since it won’t involve the extra I/O cost of an index scan.
6) Work in harmony with the query planner
Postgres asks that we place great trust in the query planner, which exists to compose together the best option from among a very large toolkit. In turn, Postgres doesn’t expose simple APIs for controlling query execution, such as MySQL’s Index Hints API. While it does expose some tools for “influencing” how the query planner behaves, wide usage is discouraged.
Postgres couples its deference to the query planner with a powerful debugging toolkit. The EXPLAIN command allows us to inspect the query planner results in complete detail. You can use this to introspect the type of index scan being used, and thus determine if you're using the most optimal path.
If Postgres is choosing what seems like inefficient scans, it may be time to rethink your index design.
In conclusion: a short guide to Postgres index strategy
This post focuses on standard B-tree indexes, and we didn’t even cover all possible index models available (hello, partial indexes).
Even so, we can distill things down here to a rough guide on how to think through indexing strategy in most Postgres databases:
- Every index has a read and write cost. Postgres considers these costs for each query to determine which indexes to use.
- The more selective your index, the more efficient it becomes to read data from the table itself. But, more selective indexes (multicolumn indexes, sorted indexes, partial indexes) require specific query patterns to maximize this efficiency.
- For tables with highly variable query patterns, the best strategy for most cases is to use many single-field indexes and let the query planner choose bitmap index scan combinations.
- For tables with highly consistent query patterns, the best strategy for most use cases is to use a few complex indexes that target common, selective query patterns.
- It’s never possible to maximize performance for 100% of queries, and it’s not easy to override the query planner’s choices. So, you should focus on the strategy that will maximize efficiency for the highest percentage of queries.
As a team, we have found these points helpful as we have designed (and redesigned) indexes to maximize the efficiency of our primary database. We hope you do too.