👋 We’re Knock. We provide a set of simple APIs developers use to introduce notifications into their products, without needing to build and maintain a notification system in-house.
At Knock, we rely on AWS Kinesis to handle various high-throughput queues, like our API & workflow logging features.
We used to have a “hotspot” problem where too many Kinesis consumers would end up on a single machine during deployments (typically the first Kubernetes pod to come online would acquire most of the consumer shard locks and end up doing most of the work).
We fixed this by adding a hashring to evenly distribute consumers across our cluster.
This reduced our peak CPU utilization by a factor of 2x, boosting platform performance and resilience for all of our customers.
🥊 Consumers, leases, & race conditions
At Knock, we run a fleet of Kubernetes Pods to handle all background job processing. This includes workflow execution, sending notifications, ingesting logs, and more.
Some of our most critical queues rely on AWS Kinesis due to its scalability and high throughput. Kinesis is a streaming platform similar to Kafka, where records are read from the stream in the same order they are written. Kinesis Streams are broken up into multiple “shards”. These shards are similar to Kafka partitions, however shards can be split or merged at any time to horizontally scale a stream as read & write traffic grow.
Each of our pods starts a consumer for every Kinesis shard. For example, if we have 10 pods and 10 shards, we will have 100 consumers running at any given time. Each consumer attempts to acquire a lease for its assigned shard. This leasing mechanism ensures that each stream shard is being consumed by only one consumer at a time. Once a consumer has a lease, it starts reading and processing records. If that consumer fails for any reason, one of the other pods is always ready to take the lease and resume processing, improving platform resiliency.
Unfortunately, this can lead to an uneven distribution of active workers across our platform. When deploying a new release, our Kubernetes deployment creates new pods with the latest version of our product to replace the older version. This creates a race condition, where the first pods to start are most likely to acquire most of the leases. Unfortunately, this can cause imbalanced CPU load in the cluster.
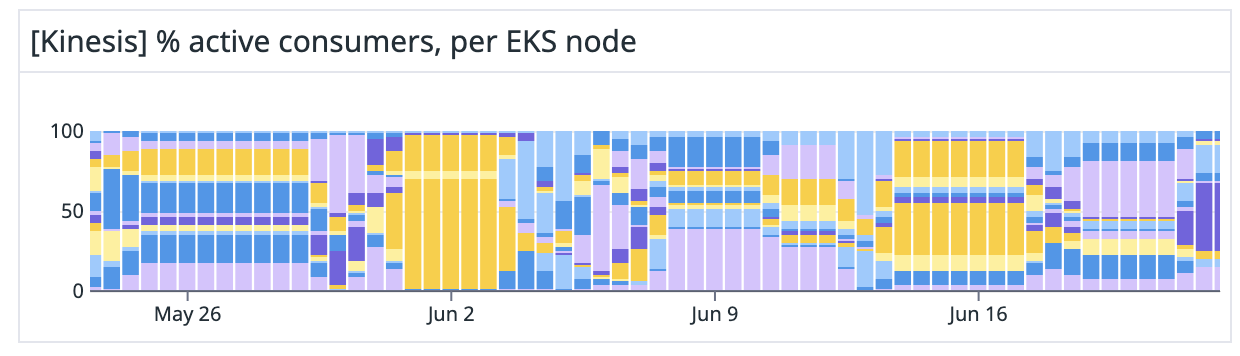
This chart from Datadog shows uneven consumer distribution. June 2nd, in particular, has a single host running more than 2/3 of all active Knock consumers! The distribution of consumers across the cluster was effectively random.
What we need is a way to ensure that each shard consumer starts only once across the entire set of running pods, while ensuring that as pods come and go the entire system is able to self-heal in the face of failures.
🛟 Hashrings to the rescue
Given a list of running pods and a list of stream shards, we need a way to designate a given consumer as the “preferred” consumer for each stream shard. The function ought to look something like this:
defmodule Hashring do
def can_acquire_lease?(consumer_name, shard_id) do
# TODO Figure this out
# Return true if we should be able to get a lease, and false if not
end
endThe way we can “figure this out” is by using a hashring. A hashring uses consistent hashing to consistently assign each consumer/shard combination to the same pod, without requiring any communication between the pods themselves. As long as the pods share the same inputs, they will come up with a consistent view of which pods should get to consume which shards for each shard consumer.
Here’s what we do:
- Hash the consumer name & shard ID together, and map that hash to a fixed range of integers from 0 to some big number (called our “keyspace”)
- Get the sorted list of pods from the same replica set as the current pod, all running the same consumer code that could acquire a lease
- Do a bit of math to match our hashed integer to just one of those pods from that sorted list
- Check if the matched pod is the current pod
For example, let’s use a keyspace of 1,000 values (starting from zero) and divide it up across eight pods (labeled as A-H in this example). Each pod owns 1/8th of the total keyspace.
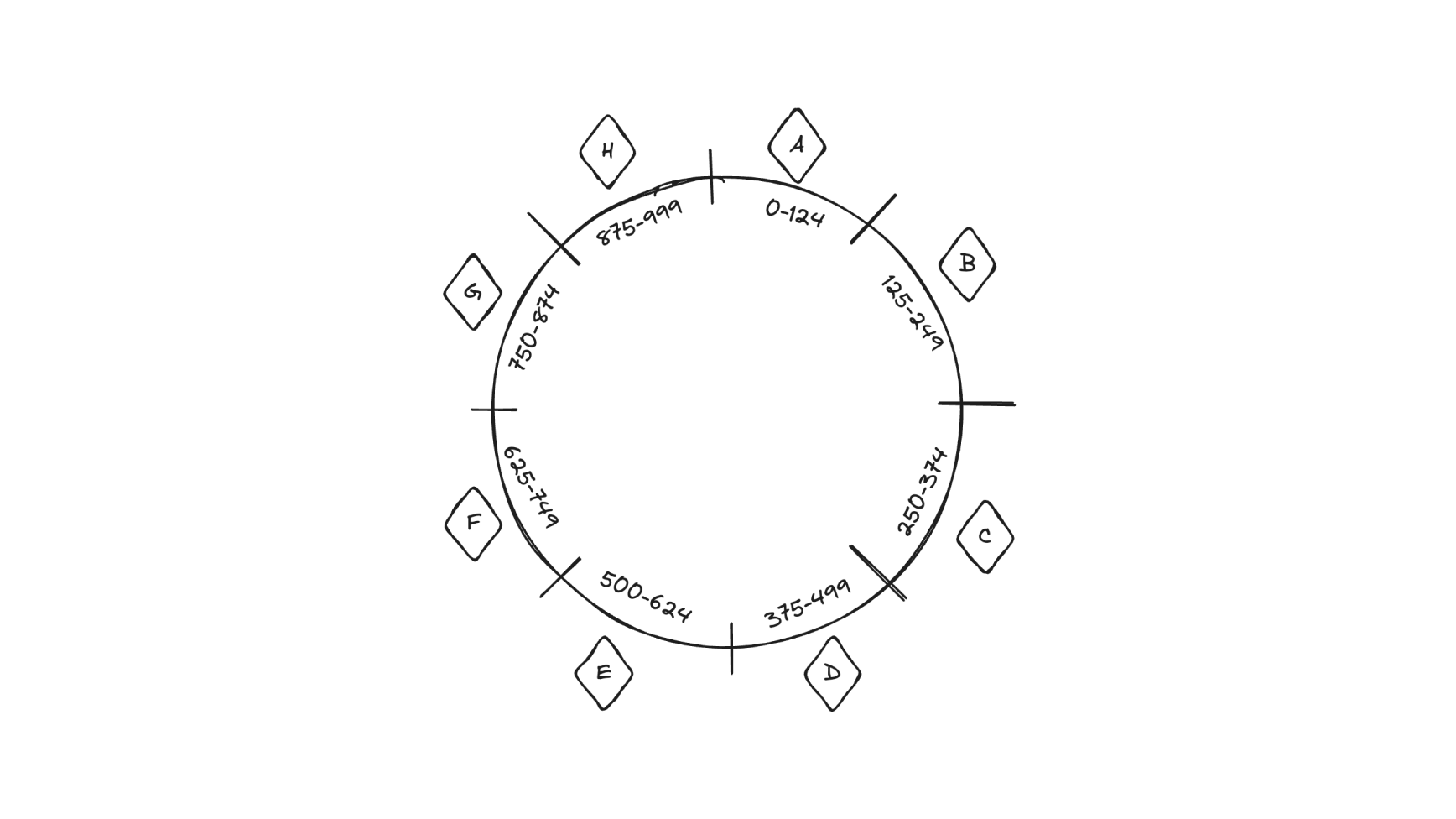
We can then hash the stream name and the shard ID into a value on the ring using a consistent hash function like Murmurhash. For Elixir applications like Knock, :erlang.phash2/2 works perfectly.
If a shard consumer’s name hashes to, say, the value 452, we can visually see on this ring that it would be assigned to pod D (where pod D “owns” all values between 375 and 499).
As long as our hashing function is deterministic & produces an even distribution of values, then our hash ring will adapt as pods & shards come and go.
Here’s roughly what the code looks like:
# The keyspace needs to be a few orders of magnitude larger
# than the max number of pods we expect to run.
# The specific value is otherwise arbitrary.
@keyspace 1_000_000_000
defmodule Hashring do
def can_acquire_lease?(consumer_name, shard_id) do
# term_hash will be an integer between 0 and 1 billion
# where the same consumer/shard_id pair will always
# evaluate to the same integer, even across Erlang
# releases. You could use a cryptographic hash,
# but this is faster and more convenient in
# BEAM-based languages like Elixir.
term_hash = :erlang.phash2({consumer_name, shard_id}, @keyspace)
# This next function is doing a lot of lifting in this example code.
# The gist of what we do here is pretty straightforward if you have
# a decent K8s client SDK in your language (we use the hex package K8s).
#
# We will need a K8s service account with:
#
# * list & get permissions for v1/Pods
# * get permission for apps/Replicasets
#
# Here are the specific K8s API calls involved:
#
# 1. Get the pod spec for the current pod
# using `GET /api/v1/namespaces/{namespace}/pods/{name}`
# (the HOSTNAME environment variable is the name of the current pod)
# 2. Look in the metadata.ownerReferences field of that pod spec to get
# the name of the current ReplicaSet
# 3. Get that ReplicaSet's spec
# using `GET /apis/apps/v1/namespaces/{namespace}/replicasets/{name}`
# 4. List all the pod specs that use the same selector as the one in that
# ReplicaSet's spec
# using `GET /api/v1/namespaces/{namespace}/pods` and the selector parameter
# 5. Sort & return the list of pod names from those pod specs
#
# We cache the name of the current ReplicaSet so that subsequent calls
# just have to list pods by selector.
#
# To speed up calls by kcl_ex, we also cache the sorted list of pod names
# and refresh that cache every few seconds. This keeps K8s API pressure
# low while letting us scale to as many concurrent consumers as needed.
#
# Another option here would be to look at using the `watch` feature so that
# changes in the list of Pods in the replica set would be evaluated in realtime.
# For us, we felt polling was simpler to implement, maintain, and works just as
# well for our use case.
pod_names = K8sClient.get_sorted_pod_names_from_this_replica_set()
# hash_ranges tells us how many chunks we are breaking the keyspace into.
# Let's say that we have 10 pods. This means our keyspace
# is broken into 10 chunks of 100M values each.
hash_ranges = length(pod_names)
# This bit of math takes our term_hash and tells us which "chunk" or
# subset of the the keyspace it belongs to. It's a zero-indexed
# integer, which is convenient for the array lookup we do next.
assigned_hash_range = floor(hash_ranges * (term_hash / @keyspace))
# Grab the pod name that belongs to that index.
assigned_pod_name = Enum.at(pod_names, assigned_hash_range)
# Is this that pod?
current_pod_name == assigned_pod_name
end
endWhy use a huge keyspace?
Although you could replace @keyspace with length(pod_names) and skip a bit of math, by assigning each hashed term to a range of values in a bigger keyspace, you reduce the probability that a change in the list of pods will force the consumer to drop its lease.
Without this step, adding or removing a single pod will force all leases to shuffle all over the cluster. As long as the keyspace is more than 2x the number of total pods you’ll ever have in the cluster, you should be fine (although one billion may be conservative for Knock’s future growth potential 🚀).
You could also consider assigning each consumer-shard to at least two pods, so that there is always a backup consumer ready to acquire a lease if the primary consumer goes down. The number of backup pods should be more than one for redundancy but not too high, or else you may end up with “hotspot” pods & hosts, reducing the value of the hashring.
We extended our fork of kcl_ex to include an optional can_acquire_lease?/1 callback. Our consumers call our Hashring.can_acquire_lease?/2 function in this callback. If the function evaluates to true, the consumer knows it can attempt to acquire a lease. On false, the consumer skips lease acquisition entirely, freeing up otherwise wasted CPU cycles & network traffic against Dynamo.
☄️ Impact & Results
After implementing this hash ring for our consumers, the balance of consumers in our cluster went from this…
…to this:
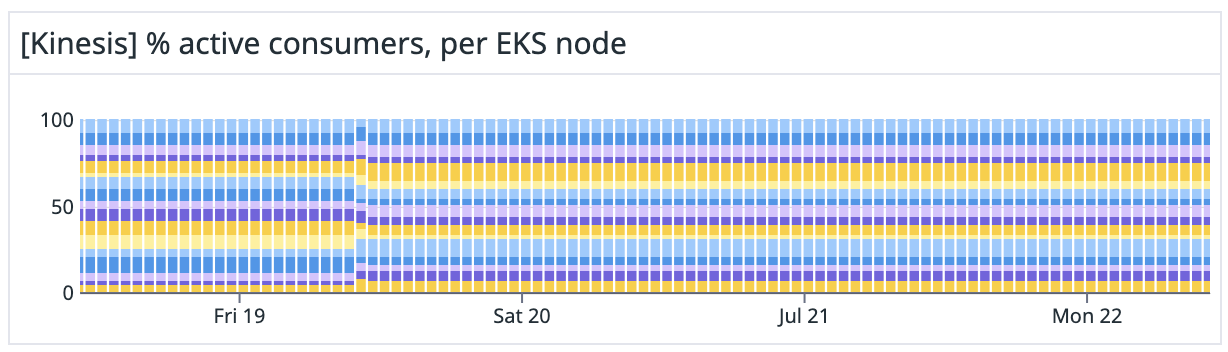
It also cut CPU utilization in half on our hottest node on a typical deploy.
Before distributing consumers this way, if we ended up with a single “hot” pod or EC2 node, we would sometimes have to manually intervene by terminating a pod or restarting a group of consumers, hoping that the consumers would naturally rebalance even though the distribution would probably still end up uneven.
Now, every deploy turns out perfectly balanced and even, giving us more consistent deployment characteristics & platform reliability between deploys.
One tradeoff to this new system is that if a consumer fails, the pod running that consumer must handle resuming processing on its own. OTP supervision trees in Elixir along with Kubernetes pod-level monitoring give us confidence that this will always happen reliably in the face of failure.
The goal, as always, is delivering the most reliable & performant notifications solution, sweating the details of every part of our platform so our customers don’t have to.