Shipping is the life blood of a startup. The faster you ship, the faster you learn, and the faster you move towards finding product-market fit and reaching that first existential milestone for an early-stage startup.
This doesn't mean that product is the only thing that matters, and it doesn't mean you should become a feature factory and blindly crank out features. You have to talk to customers, build the right solution for their problem, and ensure those customers know about your product (enter: distribution.) What it means is that if you're doing all of those things right, then you should strive to deliver that value to customers as quickly as possible. At a startup, where it's a small core team that's working to deliver value to customers, removing friction from your development process is one of the highest leverage activities available to you.
At Knock, everything we do is geared towards eliminating friction from our development process. Our goal is to go from "idea" to "value shipped to customers" as fast as we can. We're early and still figuring things out, but we wanted to share what we're doing today to enable this and see what we can learn from others in the community.
Our engineering principles for shipping
1. Trunk-based development
We lean into the practices of trunk-based development for our feature work. That means small, short-lived branches that aim to get code into the "trunk" (for us the main branch) frequently. The idea here is that the faster we can merge code into trunk, the more we can de-risk the integration of that code.
Automation and CI/CD
To accompany our trunk-based development, we've leaned heavily into CI and CD from day one. Our process for deploying right now looks like:
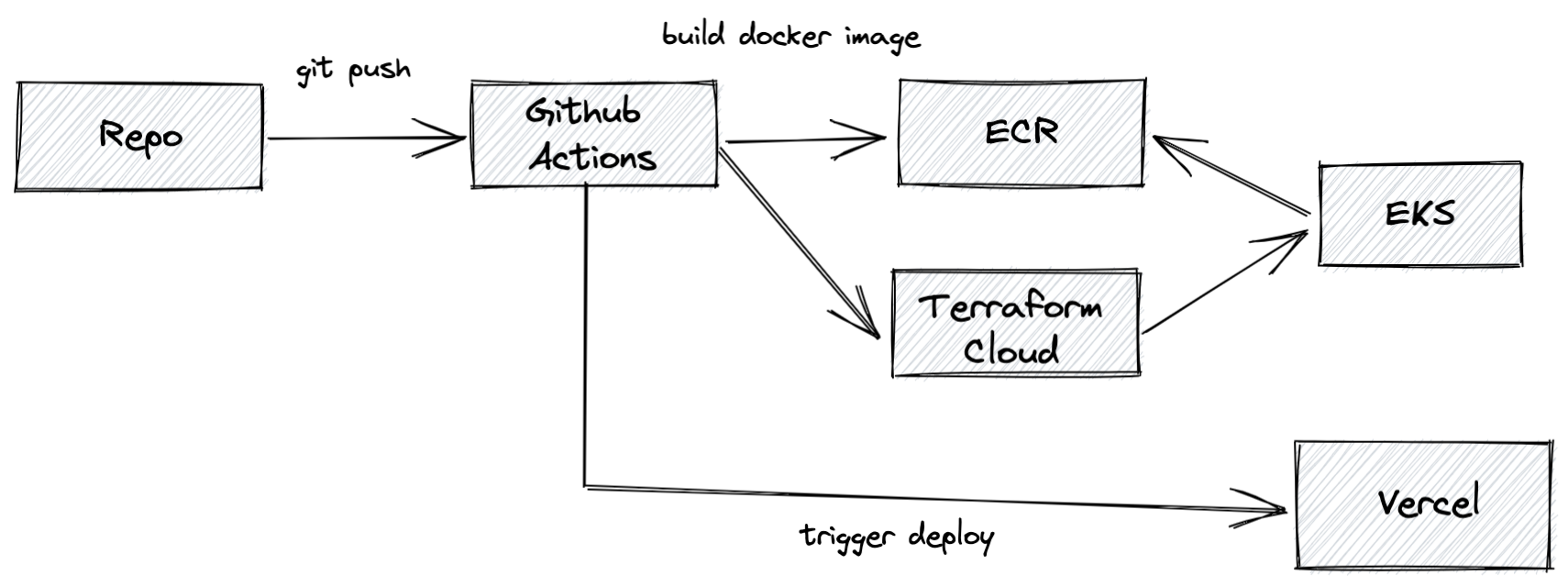
- All CI / CD is run using GitHub actions. Pull requests run our test and check suite (including linting and formatting checks) on every push.
- When a branch is merged into
mainwe build one or more new containers, push them to ECR, trigger a new deployment in Terraform Cloud, and signal Vercel to deploy for front-end assets. This all happens in our development environment. - Production releases are semantic version tags (
vX.X.X) on a repository that follow the same build process asmain, just deployed to our production environment.
Feature flagging is key 🔑
All of the features we develop leverage feature flags to ensure we can decouple deployment from release. We use LaunchDarkly to power our feature flags on both the front-end and backend (via their React and Erlang libraries, respectively). This means we can move fast, isolate new work, and deploy to customers safely with the ability to release a feature when we feel it's ready.
A quick aside: don't build your own feature flagging system. LaunchDarkly or Split.io are great tools and give you so much power out of the box, especially when it comes to targeting users with enabled flags.
More practices for trunk-based development
- All of our features must have a smattering of tests. At the very least this means integration tests, but more often than not this means unit tests as well. We're not tracking code coverage at the moment.
- We enforce branch protection on
mainand all of our code must be landed via a pull request that has at least one approver. As we're a small team, this approval can be from anyone on the team. - We make heavy use of linting and automated formatting tools to enforce conventions in our codebase. For us this means linting via ESLint in Typescript, and Credo in Elixir, and for formatting Prettier in Typescript and
mix formatin Elixir. We use a consistent configuration between our repos for consistency. - Our CI runs are fast. Typically our entire run takes ~1 minute to run, for both backend and frontend projects. We're fortunate here that we get a fast, concurrent test suite out of the box with Elixir and ExUnit. Even with this great toolchain maintaining a fast test suite requires effort but it pays dividends in shortening the feedback time and increasing engineering velocity.
- If
mainis not "green", it's the top priority for the team to get it back to a good, deployable state. A blocked trunk means we can't ship value to our customers.
2. We only ship high quality product
This might seem antithetical to our goal of increasing developer velocity to ship value quickly, but the key here is value. We believe that each and every feature we build and deliver needs to feel cohesive, work near flawlessly, and be the best iteration of itself for it to be valuable.
For us this means looking at a preview builds (we ❤️ Vercel for this), pulling down a branch and running it locally, or making the feature accessible to everyone internally via our feature flagging system. We put a good ol' fleshy human in the middle of our process here and use this step as chance to do QA, but also to see how a feature "feels" once built.
We temper this process with focus on what we can ship in the shortest amount of time, so this often means a discussion on scope: what's required to launch the feature, what's a fast follow, and what we can punt to the backlog. When teams want to move fast, they often think they must do so at the expense of quality. At Knock, we believe in appropriately scoping our work so we can ship high-quality product, fast.
3. Deploying isn't a ceremony
You might think that this point sounds obvious, but in an early-stage startup environment it's too easy to get into a habit in which only one person on the team manages deployment. To counter this, we've tried to make it easy for everyone on the team to ship code to customers.
We continuously deploy our main branch to our development environment, which is a perfect mirror of our production environment, minus real customer data. When we want to release the current code into production, we trigger a bot in Slack that any one on the team can invoke. This bot will:
- Gather all of the commits and PRs between
mainand our last tagged version. - Extract all of the Linear tickets from the PRs.
- Generate a changelog of what's going out, with a link to the author who wrote the PR.
- Tag our code by bumping the minor version, and generate a new GitHub release.
- Post a neat little message into Slack showing you the changelog, and tagging the appropriate team member.
All of this happens just by running /release cut repo where repo is the name of the repository we want to push a release of.
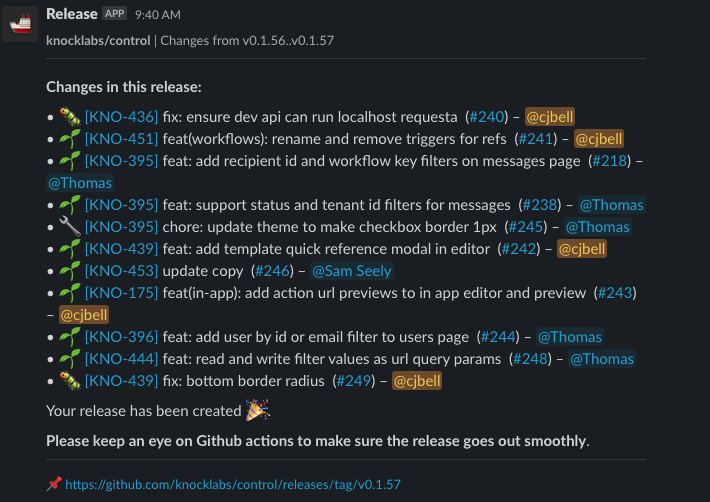
What a particularly busy day of commits looks like on one of our repositories (control).
Why tickets over commits?
We believe that the ticket going out better reflects the value going to customers over a single commit, and as such we show the ticket in our release notes.
4. Capture changes in our changelog
We take turns writing our weekly changelog that includes all of the features we shipped over the past week. This isn't a particularly novel process, and much has been written on the benefits of having a changelog.
What we've found from writing ours is:
- It's a great way to focus on the value we're shipping to customers. We start each week with a planning session in which we think about "what we're going to put in our changelog". That's not the only thing we're planning work around, but it does drive urgency within the team that we need to ship customer value each and every week.
- It serves as a reminder of all we've achieved. Being able to easily scroll back in time and see everything we've shipped over the last however many months is a real reminder of the continuous forward progress we're making as a team.
- It shows momentum to customers and to future members of the team. Prospective and existing customers get to see how fast we deliver value on a regular cadence. Potential hires get to see they're joining a team where they'll get to have an impact in week one.
5. Optimize for developer autonomy
As a small team, we've prioritized hiring product-focused generalists who care deeply about building and delivering customer value. In order to optimize our velocity and our ability to ship features, our engineers work on single features where they design and build the feature end-to-end (from product brief to infra, all the way through to UI).
This style of working means that we can parallelize our work and reduce our coordination costs. It's one of the true luxuries of working on a product with a focused surface area, and a small, lean team.
This comes with the tradeoff that engineers working on separate features means less shared context on what each other is working on—code reviews and pairing can become more difficult. We believe this is the right tradeoff for us to make as a small team where ownership and empowering engineers to own features leads to increased velocity, and we are actively looking at ways of helping with shared context.
Future considerations
- Ensuring that we cut a release from
mainregularly. Given that we have a process where we tag main, we've had situations whereby it's been a few days since we deployed and this means we're building up a lot of code that's not yet running in production. A few ideas here include running a bot to send a regular reminder when there's work building up, or have a rotating release owner for the week. - Developing our practices / tooling for rollbacks. We haven't got this nailed yet, and we have a preference right now to fix forward rather than rollback. But as we add more members to the team, the needs here increase.
- Reusing containers from development in production. We currently rebuild a container when tagging main for a production deploy because we're using separate ECR repositories. Instead, we can reuse the SHA tagged container we built in development, shaving around ~5 minutes off of our production deploy time.
- (Eventually) Continuously deploying
main. Doing so mitigates the need for the first bullet in this list, but it also means that we'll need better tooling to detect errors on deploy, and likely even more tests to feel confident before we push out code to customers.
Wrapping up
That gives you a small peek into how we do things over here at Knock.
All of the above is delivered with the caveat that we're a small team today, and what's working for us now may not work for us later. For now, this process helps us to remove friction in shipping value to our customers. We believe that's critical in increasing our chances of succeeding as a viable product, and business, over the long term.
We'd love to hear about how your team ships code to your customers 💖