In this post we’ll explore best practices in building a webhook system and how we built ours on top of Knock’s existing notification engine.
What are webhooks and how are they used in Knock?
A webhook is a way for web applications to deliver real-time data to each other. It is an API endpoint set up on one application that the other will call when a pre-defined event occurs. In Knock, users set up a unique URL on their own application and provide it to Knock so that when notification event occurs, such as a sent message, it will deliver the data about that event to the endpoint.
Here are some common use cases for using Knock’s webhooks:
- Storing messages longer than our internal retention period
- Populating a custom log of the messages sent to individual users in your system
- Executing a side-effect in your application if a specific event occurs
You can read the full documentation on outbound webhooks in Knock here.
Best practices for building webhooks
We looked at best-in-class webhook systems for inspiration and leaned on WorkOS's guidelines and Stripe’s documentation among others to guide our design decisions. We took the following practices into consideration.
Event types
Make sure you allow users to opt-in to the specific events they’re interested in receiving. It’s important to gather feedback from users around how to categorize what their systems will care about so that product and engineering can properly define the events they want to expose. For example, we determined users would want information about their entire notification lifecycle, not just when a message was sent or delivered. But we also recognized that it would be more useful to separate those status changes into separate events rather than a blanket event for “status changes” on a message, so that a user can opt into “message archived” but not need to receive information about “message read”.
Delivery attempts and retries
Your system should record every attempt made to deliver the message to the end user, and have built-in retries that back off exponentially to account for various states of the end user’s server. Define a contract with users so their endpoint will send a 2xx response, letting your system know it’s been delivered. Knock’s system attempts to send a webhook eight times, which is the same as it handles notification delivery. We also expose those attempts to the user in the webhook dashboard so that they can see when something’s gone wrong, and allow a user to disable webhooks when needed.
API versions
Because Knock is on its v1 API we don’t need to include a version in these first events, but when we eventually upgrade to a v2 we’ll begin to include version signifiers in the event payload. This will enable user applications to properly parse the events they receive.
Event handling
We include a unique ID on our events so that the end user can handle idempotency. We ensure that we send events at least once, but that can mean that occasionally they’ll be sent more than once, so it’s important to convey to users that they should set up their system to recognize duplicate events. Events may also be sent out of order so we include timestamp data about the event itself as well as when the status change occurred in our system.
Security
Because events received by a user’s webhook endpoint can be forged, we include a security token in the header that we encourage users to verify before processing webhook events from Knock. This is a common practice and an easy way to validate the data coming into your application is from a trusted source. Here’s how to recreate that process when building your own webhook implementation.
Building webhooks on top of Knock’s notification engine
At the outset of the project, we weighed three options for building Knock’s webhook system:
- Use an outside vendor
- Build a net-new webhook domain and infrastructure
- Building webhooks as an extension of our notification engine
We love to rely on third-party APIs for services in Knock, and could have used a webhook-as-a-service provider like Svix, Hookdeck or Hookrelay for this implementation. However, we see webhook delivery as being an extension of our core competency in delivering messages to third party services, predominantly via HTTP, so we decided against buying this feature. Using a vendor would also have inhibited our ability to be included as an on-premises application.
Building a new webhook service outside of our main delivery service would have been simple and straightforward, but as we started evaluating the best practices in our domain design, we realized that we had already built much of what would need to comprise the webhook system within our own notification engine. This is a robust delivery system with all of the infrastructure already in place for scaling it as we grow. Additionally, we had a framework for recording delivery attempts and displaying those to our users. It would be a show of confidence in our own work to rely on this foundational piece of our system to power a new one.
How does it work?
With all those considerations in mind, we decided to build our webhook service on top of our notification delivery and workflow service.
Under the hood, a “webhook” is actually a workflow with a single channel, our internal HTTP channel, that delivers an HTTP request to a configured endpoint. When a user-defined workflow is triggered, it creates a series of events that are recorded along the way: message.sent, message.delivered, message.read, etc.
We added a step to this process in which we record these events about messages into a message log to be consumed by other services (including our new webhooks service).
Secondly, we built a new consumer for our message events stream that handles our webhook broadcasts. When consuming the message events, it performs a cached lookup to an event-mapping table. This table has user-defined webhook endpoints and their desired events along with the webhook workflow that was generated when they created the webhook in the Knock dashboard.
Lastly, it triggers the webhook workflow(s) it finds, which engages our own notification engine to deliver it in the exact same way it would a user-triggered workflow. So for any triggered user-defined workflow, any n number of system-defined webhook workflows could be triggered as a result.
Webhook flow
When a user sets up a webhook in the Knock dashboard, internally Knock creates:
- A webhook workflow with a single HTTP channel step
- A mapping of that workflow to the events they’ve selected
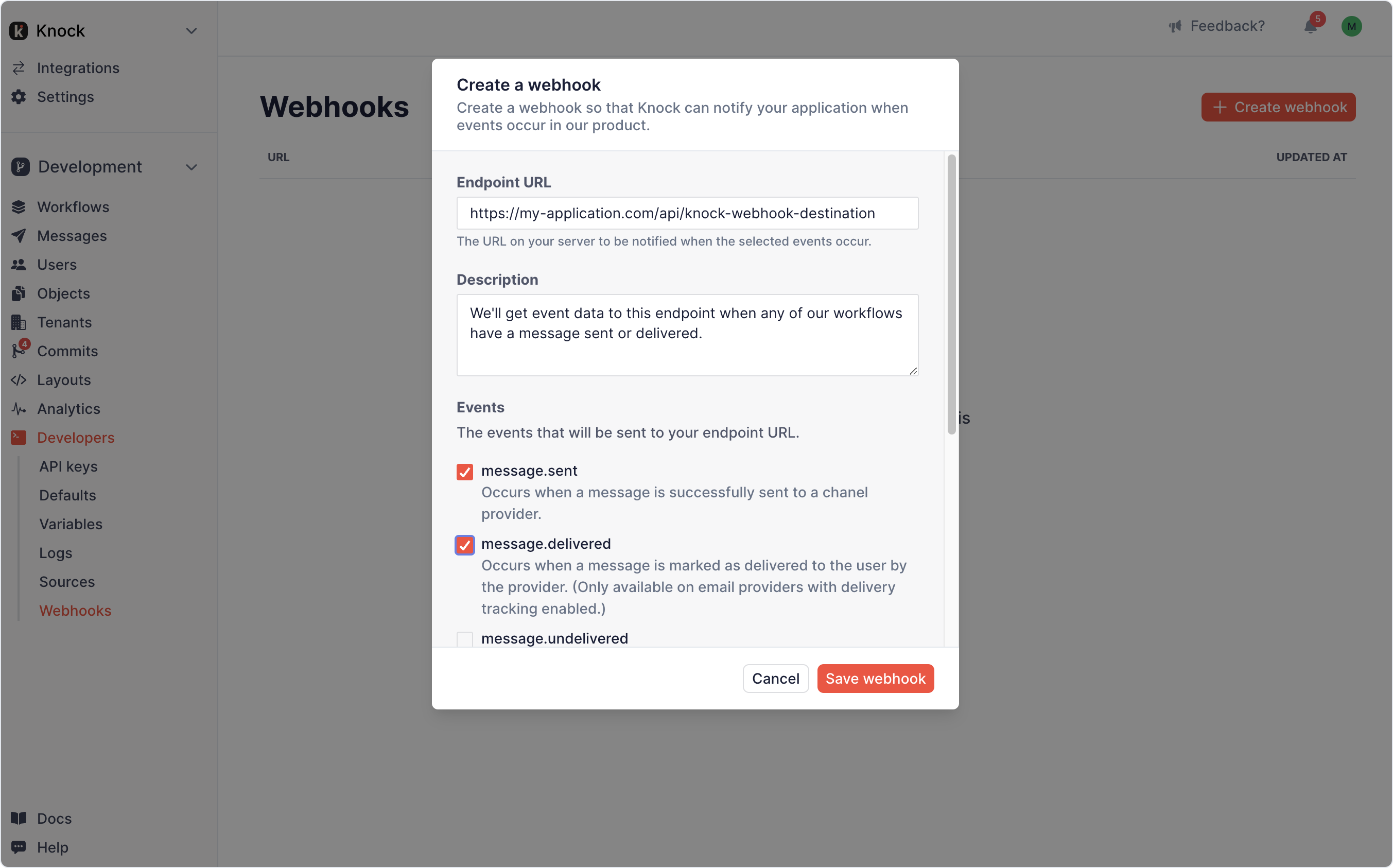
So when the user creates the above webhook, they provide an endpoint in their own application that Knock will send event data to for any of their active workflows upon the message status being “sent” or “delivered”. All the message events will be recorded and sent through the flow, but only the message.sent and message.delivered will kick off the webhook workflow that’s been created for them.
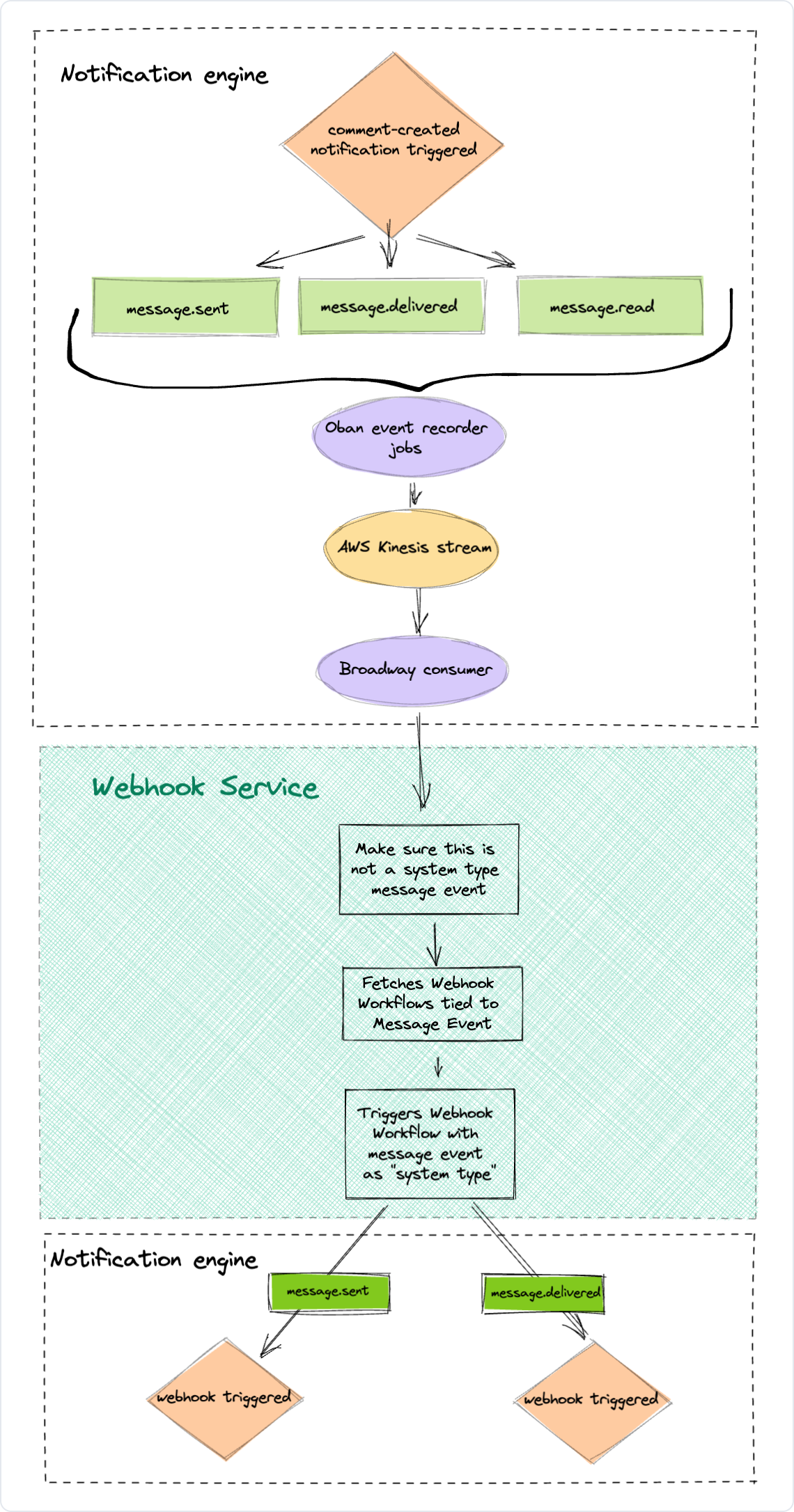
As our system grows we also have an easy way to separate the infrastructure resources used by user- and system- notification delivery to provision additional capacity to each.
Costs and benefits
The potential downside of this architecture was that we’ve introduced what feels like notification Russian nesting dolls into our system, which could increase the cognitive load for a developer new to the space when trying to understand that a notification kicks off other notifications. However, this is outweighed by the benefit of essentially only needing to understand and maintain a single delivery system throughout the product offerings. Elixir’s organization of domains into contexts have helped us keep our definitions and purposes clear, and we’ve also leaned heavily on tools like Oban to help us manage a complex asynchronous set of steps.
A last consideration is that we now have the ability to expose webhooks as a much more robust feature in the future. Since they are simply a workflow with a single channel step, we have the opportunity for us to open them up to our users at some point for more complex notifications.
Overall we're happy with the decision we made to rely on our existing system for this setup since we were able to reuse so much of the foundational notification infrastructure we've already developed and the potential it has for feature expansion in the future.