👋 We're Knock. We provide a set of simple APIs and a dashboard that developers use to introduce transactional notifications into their products, without having to build and maintain a notification system in-house.
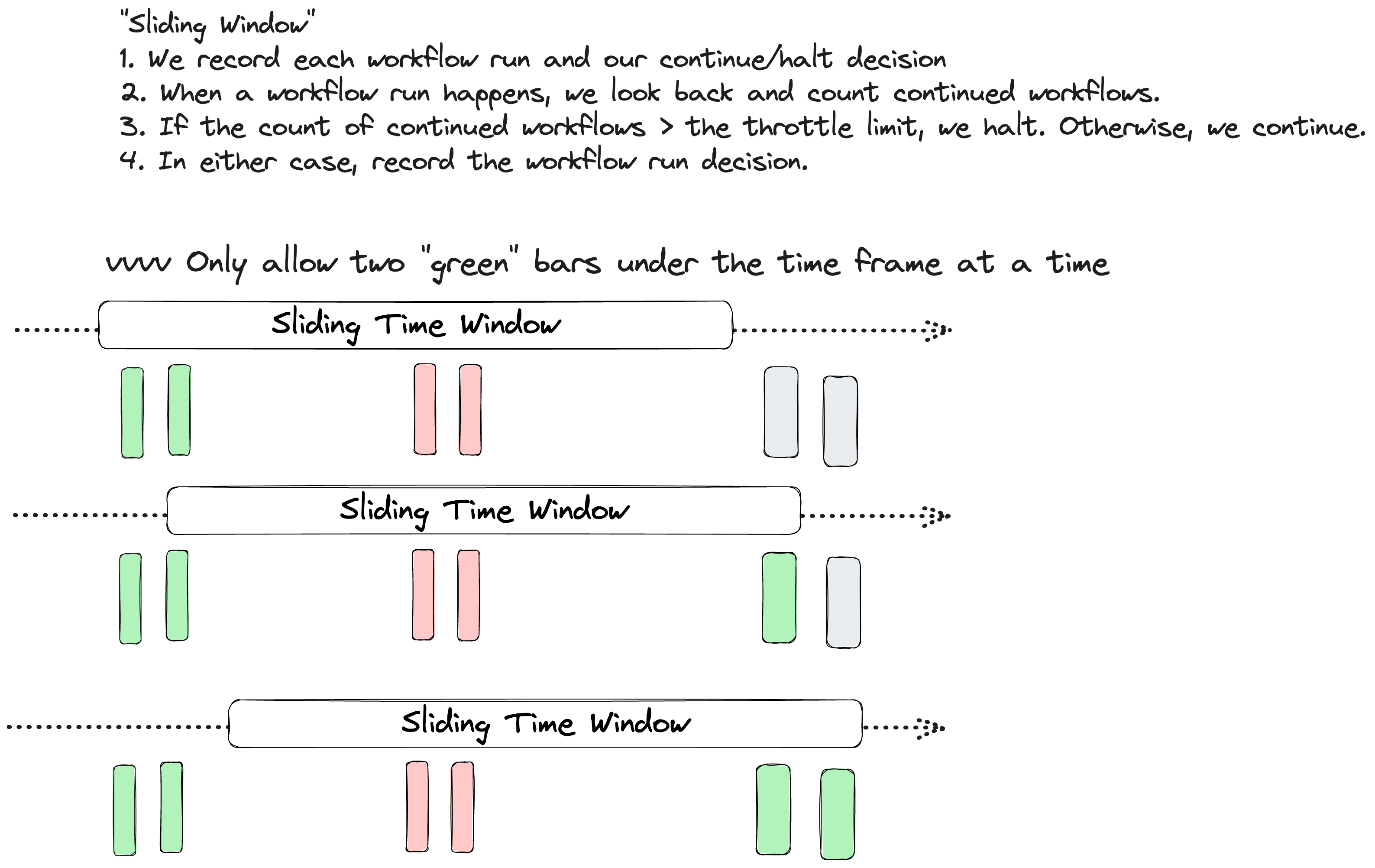
We recently added a Throttle Function as a step in our notification workflow engine. Using a throttle step makes it easy to regulate a workflow being triggered too frequently per recipient. If a throttle limit is exceeded, a workflow run will be stopped by the throttle step until some time has passed, allowing the throttle to "cool down" and start allowing workflow runs again.
Each throttle step needs to keep track of three things:
- A "throttle window" duration (for us, that is between 1 second and 31 days)
- A limit to the number of workflows that can run over that window
- A key by which to scope the throttle. By default, each throttle step is scoped by the combined workflow step and recipient. Optionally, an additional key can be drawn from the notify data to fine tune a throttle key.
When a throttle step runs:
- Look back over the throttle window and count how many workflows have happened for the given throttle key
- If that count exceeds our throttle limit, we halt
- If not, we continue
With this design in mind, we set out to build a system that would support this design at scale. Building throttle steps reinforced that having a clear design up front and using the right data structures make it easy to solve even tricky problems like throttling.
TL;DR: Match a real customer problem with the right data structure, and the right data structure with the right infrastructure.
Redis supports multiple data structures, including Streams. A stream is a set of ordered timestamped records. By recording each allowed workflow run in a unique stream per throttle key, we can easily compare our throttle limit with how many workflow runs have happened over our throttle window. Redis also makes it easy to expire old records and entire streams to keep our memory utilization low.
On data structures
At Knock, every feature is designed to solve a real customer problem. For every customer problem, we like to go broad and explore multiple potential solution designs. We can then consider tradeoffs like time-to-market, how a solution will scale over time, and how easy it is to maintain.
Once we anchor a design against real customer problems, we can start to figure out the right technology to support the design. More often than not, the right technology is built on a foundation of having the right data structures.
Data dominates. If you've chosen the right data structures and organized things well, the algorithms will almost always be self-evident. Data structures, not algorithms, are central to programming.
~ Rob Pike's 5 rules of programming
The throttle step was no exception: getting the data structures right is often the first step in building the technical side of a solution.
We knew that the throttle window was key to designing this feature. When a throttle step runs, it looks back over the throttle window - but what should it look at? How should this record of data be structured?
At first, we considered some kind of counter. That, however, doesn't include the necessary time information since the throttle window is a "sliding" window that is constantly advancing. Although background jobs could be created to decrement the counter after some time, that seemed needlessly complex.
The drawing board
We then started considering ordered data structures. If there was a way to keep a record of each time a throttle step passed passed in chronological order, and if that order included the time of the workflow run, we could come up with a count of allowed workflow runs and compare that with our workflow limit.
When considering persistent data structures, we most commonly think first of relational databases. A relational database that records each passed throttle step would have two parts:
- An append-only table for logging passed throttle steps by throttle key & timestamp
- A way to expire old rows so the table doesn't grow indefinitely
Although this solves the basic problem, we were concerned that at scale this would put unnecessary read & write pressure on our relational database. At high volumes, a single Postgres table (even partitioned) can quickly become a bottleneck or even affect other parts of the system.
Walking through this design did yield a key insight: The underlying data structure we needed was a temporally ordered, append-only data structure. What we needed was an append-only log or stream. Although that could be modeled with a database table, we wanted to evaluate other tools to support that type of data structure.
Enter Redis Streams
We use Redis to support various parts of the Knock Platform. Although famous for storing arbitrary key/value pairs, Redis supports more exotic data structures including sets (ordered and unordered), Geospatial Indexes, and append-only logs called Streams.
Redis Streams offer simple semantics: under a given key, you can append one or more records, and you can read them back in order. In this way, Redis Streams are conceptually similar to an ordered log like Apache Kafka Topics or AWS Kinesis Data Streams.
Each record in a Redis Stream has a timestamp-based ID and a value. When reading back from the stream, we can ask for all records after a certain timestamp, giving us what we need to decide if we have already exceeded our throttle limit or not.
Interestingly, we can also tell Redis to expire records that are older than that timestamp while reading. This means that in one operation we can not only figure out if we should throttle or not, but also make these data structures self-maintaining. Because a Redis Stream is just another key in Redis, we can also expire entire Streams that have completely slid past our throttle window.
Redis Streams fits our throttling use case perfectly. We can:
- Build a list of passed throttle steps, ordered by time
- Read from that list by looking back over our throttle window
- Expire stale records from a stream, or even the stream itself
- Support the throttle step without any new infrastructure (we already use Redis)
- Avoid adding unnecessary extra load to our primary database
Compared to Kafka or Kinesis Data Streams, Redis Streams are lightweight, easy to expire, and extremely fast for both reads and writes.
Handling concurrency with locks 🔐
Knock is built to handle both scale and concurrency. Although generally workflows run concurrently without any synchronization, throttle steps need to run in a serial fashion to prevent unwanted workflow runs from sneaking past in a race condition. If a throttle step should only allow one worfklow per minute, and ten workflows start running in the same second, there's a chance that all ten will run if they are all running concurrently.
To that end, when a throttle step starts executing, it acquires an exclusive lock (again, using Redis) using the throttle key. It can then execute and release the lock. If other throttle steps for the recipient & throttle key are running concurrently, they are forced to wait until they can acquire a lock as well. During execution while holding the lock, the throttle step is guaranteed to have full read & write control over its Redis Stream, ensuring all throttle steps execute serially. This prevents the race condition scenario.
Tradeoffs with Redis
Of course, no technology is without its tradeoffs. Here is how we evaluated these tradeoffs for our situation. Tradeoffs are all about capturing the nuance of your customer's expectations, your product vision, and how you intend to deliver that vision to your customers over time.
- Redis is known for being fast, not for being durable. Although running Redis as a highly available, multi-primary cluster is possible, we have decided to run our cluster in an active-passive mode. This means that some data loss will happen if our Redis primary node fails before replicating all of its data to the passive node.
- This means that we can use extremely simple Redis locks and avoid the known limitations of distributed Redis locks.
- This also means that, if there is a system failure, it is possible that our Throttle function may allow more workflow executions over a throttle window than expected. This is a risk that we accept in exchange for operating a system that is otherwise more performant and reliable than relying on a system that is 100% consistent all the time.
- Redis cannot enforce constraints from other databases. For instance, foreign key constraints in a relational database don't apply to Redis at all. Although this didn't apply to our project, some projects may require tighter data modeling constraints in the database - something that Redis cannot do.
Wrapping it up
We built our throttle step just like we approach all new features:
- What customer pains & gains are we solving for?
- What is the simplest data structure/technical solution that fits the problem?
- How can we leverage what we already have to support that simple solution?
At Knock, one of our engineering principles is to reduce complexity. Shipped features should reduce complexity for both our customers and ourselves. By anchoring solutions against customer pains and gains, staying focused on simple solutions, and reusing or refining what we already have to support those solutions, we believe we can do more with less.
Being curious about your tools and the broader technology landscape can also go a long way in knowing what is even possible with your day-to-day tech stack, or using other tools you may be unfamiliar with. Although Knock has long relied on append-only logs for a variety of tasks, we had never used Redis Streams before. Even so, by knowing about the right data structure and being curious about our tools, we were able to make the connection that Redis was the right tool for the right data structure in this scenario. By taking time to be curious about our tools, understanding different types of data structures, and fully exploring multiple solutions, we landed on the ideal solution for this feature.
Key lessons learned:
- Redis is a fantastic tool
- Be curious and learn about your tools so you know what you have at your disposal
- Match a real customer problem with the right data structure, and the right data structure with the right infrastructure